#1 Hier à 15:00
- thom_fr
Retour d'exp. passthrough RTX5090 dans une VM win 11 sous Ubuntu 22.04
** TL;DR
Installation de Linux Ubuntu sur un PC performant (Ryzen 9950X, 192GB RAM, RTX 5090) pour faire tourner une machine virtuelle de gaming sous Windows 11 et une autre machine virtuelle pour faire de l'IA sous Linux.
** Problématique
Partager un PC entre un gamer désirant une machine performante pour jouer à Flight Simulator 2024 sous Windows 11 en 4K ultra full details, et moi, désirant m'initier à l'IA self-hosted et faire tourner des LLM, des modèles txt2img, etc. sous Linux.
Ces deux usages différents nécesitent à peu près la même config: un CPU puissant, beaucoup de RAM, un backend de stockage NVME performant, et un GPU récent avec le plus de VRAM possible.
L'idée est donc d'acheter une seule fois le matériel et de partager son temps d'utilisation (les deux usages ne pourront pas être faits simultanément !).
Mais le gamer et moi habitons à 200km de distance.
Moi, je n'ai besoin que d'un accès distant en SSH à la machine pour mon usage.
Le gamer a besoin de brancher son écran dessus, donc le PC sera installé chez lui (et par conséquent il payera l'électricité ;-)
J'achète des composants pour monter un PC: carte mère, CPU, RAM, disques, etc.
On va installer sur le PC ainsi assemblé, un système d'exploitation basé sur une distribution Linux, et configurer deux machines virtuelles qui pourront être démarrées alternativement et auront un accès direct au matériel (en "passthrough").
Autres contraintes/problématiques secondaires:
- Le PC sera derrière un routeur inconnu, son adresse IP publique susceptible de changer, et le plan d'adressage IP interne n'est pas connu. Il doit cependant être accessible par moi de manière sécurisée. Ce sera donc lui qui initiera la connexion vers une machine située chez moi, en ouvrant un tunnel SSH qui devra être maintenu et se relancer automatiquement en cas de perte de connexion.
- On doit pouvoir contrôler localement le démarrage de la VM de jeu. Pour cela je prévois un petit pavé numérique USB qui permettra de contrôler la machine hôte.
- Tout devra être sauvegardé automatiquement, avec un plan de roulement/rétention sur, par exemple, 7 jours/6 semaines/6 mois. On fera des snapshots des VM selon le même plan.
- Pour le stockage, on va allouer 1TB à la VM de jeu pour commencer, en gardant la possibilité de l'étendre à chaud si nécessaire.
- On va installer plusieurs SSD NVME: 2 en passthrough pour la VM IA, et deux autres pour stocker les images disques des VM ainsi que les données.
- On va en profiter pour configurer un accès remote sur la VM de jeu sous windows 11 afin d'apporter de l'aide avec prise de main à distance si nécessaire.
- Enfin, je vais utiliser cette nouvelle machine distante de 200km pour faire des sauvegardes de toutes mes données perso loin de chez moi. On va donc prévoir un stockage lent sur un disque dur, avec une partition chiffrée.
** Choix de la carte mère
C'est un choix très important pour ce que je veux faire. Après avoir comparé les performances et les prix des CPU, le choix du moment (juillet 2025) fait qu'on s'oriente vers de l'AMD (Ryzen 9).
Concernant les fabricants de cartes mères je n'ai pas de préférence mais on va rester dans les marques grand public les plus répandues, donc: Asus, MSI, Gigabyte ou ASRock.
J'ai l'intention de mettre 4 SSD NVME dont deux Gen5, il faut donc assez de slots intégrés, et du bon type.
Je tombe rapidement sur ce modèle: Gigabyte AORUS X870E Pro.
Il est temps de vérifier les IOMMU groups.
En cherchant "aorus x870e pro manual" sur internet on tombe directement sur le manuel de cette carte mère sur le site du fabricant (lien: https://download.gigabyte.com/FileList/ … 88010155f8). En page 5 figure le diagramme des composants intégrés:
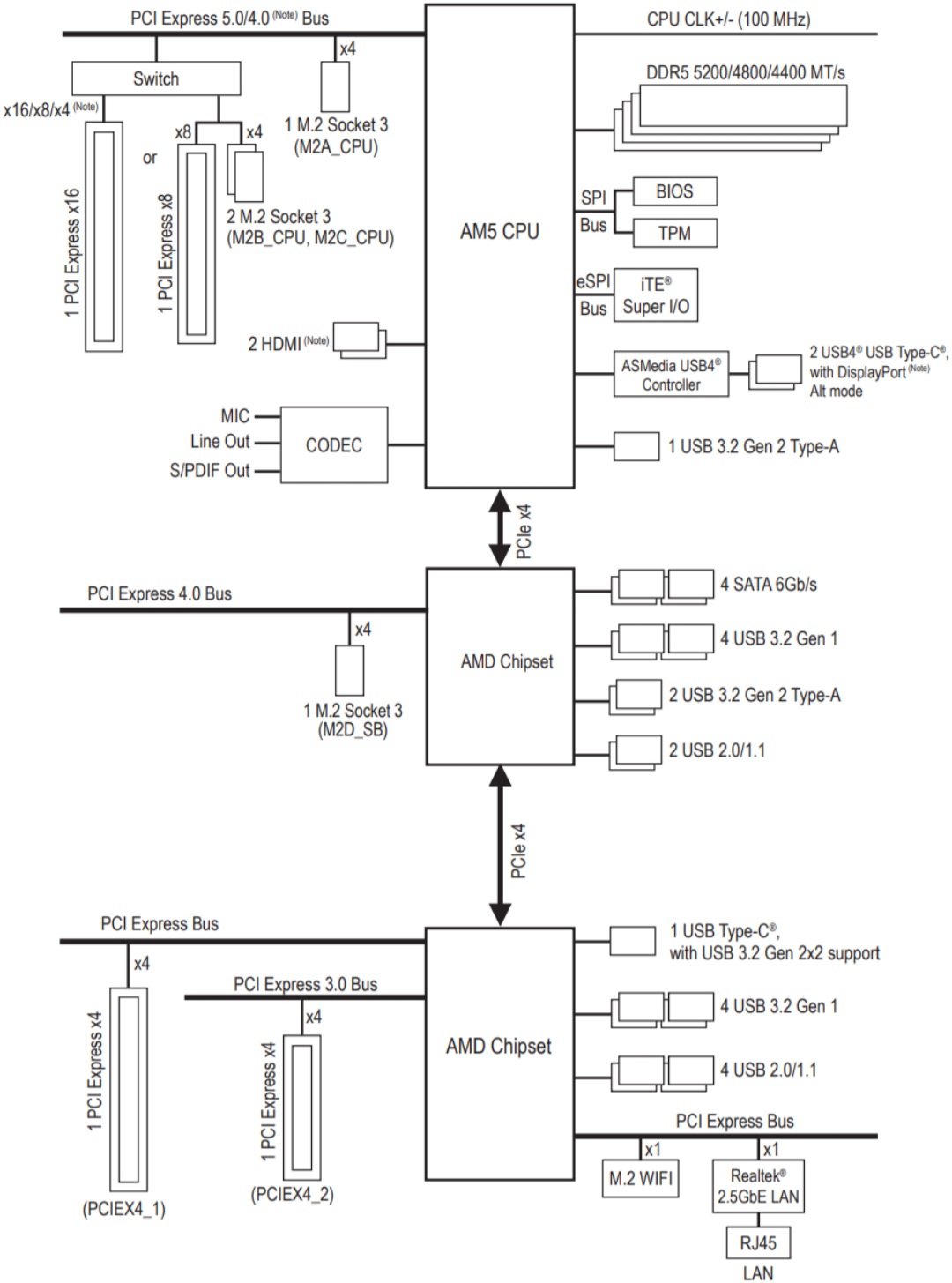
Ce que je souhaite faire, c'est passer en "passthrough" le hardware suivant à mes VMs:
- la carte graphique,
- les deux SSD NVME Gen5,
- une carte PCIe USB3 (car la VM de jeu va avoir besoin de devices USB physiques, au minimum un clavier et une souris. On a une autre possibilité qui est de passer les périphériques USB individuellement, mais la dernière fois que j'ai essayé c'était instable et moins performant).
Une problématique pour passer du matériel en direct à une VM est de tenir compte des groupes IOMMU.
En gros, chaque composant qui est sur une ligne (un bus) qui sort directement du CPU sur le diagramme de la carte mère, est isolé dans sa propre zone d'adressage de mémoire: on peut le passer à une VM. Pour les composants qui ne sont pas directement reliés au CPU c'est plus compliqué: ils sont probablement regroupés par chipset, et il ne sera pas possible de donner le contrôle d'un seul d'entre eux à une VM (il faut lui présenter le groupe en entier). Parfois ça peut fonctionner, mais c'est incertain.
Sur le schéma, on voit que le slot PCI Express 16x est derrière un switch PCI sur son propre bus, donc c'est OK: on pourra installer une carte graphique dans ce slot et la passer à une VM.
Les deux SSD NVME à passer aux VM sont des Gen5. Sur la carte mère il y a trois slots M.2 Gen5 et un slot Gen4. D'après le plan de la carte mère qui se trouve en page 4 du manuel, les slots Gen5 sont ceux nommés M2A_CPU, M2B_CPU et M2C_CPU. Ils sont tous sur un bus directement relié au CPU, donc on pourra installer dedans des SSD NVME et les passer individuellement aux machines virtuelles.
En revanche, les deux autres slots PCIe physiques de la carte mère sont sur un autre chipset et n'ont pas de switch PCIe dédié, cela veut dire qu'ils risquent de partager un groupe IOMMU commun avec tous les devices gérés par ce chipset (donc: le Wifi, 9 ports USB, et le port RJ45 2.5 GbE). On devrait passer tous ces périphériques en un seul lot à la VM, la machine hôte n'en aurait plus le contrôle, donc on perdrait le réseau: ça ne peut pas fonctionner.
Mais heureusement, le contrôleur USB4 intégré a son propre bus avec le CPU, il sera isolé dans un groupe IOMMU à lui. Donc, même pas besoin d'acheter une carte PCIe USB3, on pourra passer le contrôleur USB4 à une VM. Sur les photos de la carte mère, il y a deux ports de type C en USB4, donc on pourra brancher deux petits hubs USB dessus, comme ça on aura plein de ports.
Curieusement, il y a aussi un port USB 3.2 qui se retrouve tout seul sur un bus avec le CPU rien que pour lui, donc éventuellement on pourra aussi passer ce port à la VM (pour savoir où il se trouve sur la carte mère, on peut par exemple essayer de brancher un device USB successivement sur tous les ports USB un par un, pour déterminer à quel emplacement physique notre port USB 3.2 est situé).
C'est plutôt souhaitable que le fabricant de la carte mère publie dans sa documentation un diagramme des composants intégrés. Précisons que, pour les modèle équivalents que j'ai trouvé, ASRock affiche dans sa documentation le diagramme d'archi de sa carte mère, mais Asus et MSI ne fournissent pas l'information.
Normalement, il y a toujours moyen de s'en sortir d'une façon ou d'une autre mais j'ai déjà vu passer sur les forums des messages inquiétants de setups avec du passthrough impossibles à faire marcher sur certaines combinaisons de matériel, donc je préfère être certain au moment de commander.
L'isolation des groupes IOMMU ne dépend pas que de la carte mère, elle dépend aussi du CPU, donc en fonction du modèle choisi, il faut s'assurer en parcourant les forums, que quelqu'un a déjà réussi à le faire. Pour la combinaison Aorus X870E Pro + Ryzen 9950X + RTX 5090, je valide.
Il y a aussi des cartes mères plus haut de gamme (les versions "Extreme" ou "Platinum") qui apportent une fonctionnalité "ACS" (pour Access Control System) qui permet d'activer une isolation logique au niveau du BIOS (sur les cartes mères à chipset AMD cela se configure dans le menu "AMD CBS") si cela peut aider.
Enfin dans le pire des cas, il est toujours possible de séparer les devices dans le système en patchant le noyau Linux (avec un patch "ACS override"), c'est très intéressant mais aussi un peu risqué et on n'est pas là pour ça donc je veux absolument l'éviter (gestion des mises à jour...).
Dernière chose: lorsqu'une VM avec un GPU en passthrough est démarrée, la machine hôte ne peut plus rien afficher sur cette carte graphique car elle n'y a plus accès. Si on veut qu'elle puisse afficher quelque chose (pour continuer d'utiliser la machine hôte en direct avec un clavier/écran, ou pour du diagnostic) il faut une carte mère avec un port HDMI intégré et, soit un chipset graphique intégré, soit une compatibilité avec un chipset graphique intégré au CPU (et bien sûr un CPU adéquat).
** Choix de l'OS
Ce point est très important également. Il me faut un noyau récent (6.8 minimum pour supporter le matériel récent), un support long terme, et je veux du ZFS qui me permettra d'avoir de la compression lz4 plus légère et performante que la compression zstd de Btrfs, ce qui sera un point crucial pour la performance de mon setup.
Au moment du choix (juillet 2025), la dernière distribution Debian (12.11) vient avec un noyau 6.1 (le 6.8 est dans la Debian "testing") et toujours sans support natif de ZFS ce qui oblige à charger un module DKMS pour en bénéficier (avec quelques faibles risques que ça ne fonctionne plus pareil après un upgrade de noyau).
Le choix pragmatique est donc Ubuntu Server 24.04, pour le noyau plus récent + les drivers matériels non-libres inclus + les mises à jour de sécurité pendant 10 ans + le support natif de ZFS.
Il y a peut-être mieux ailleurs, notamment du côté de Arch ou Fedora mais je ne les connais pas.
Avec Ubuntu on a les "snaps", un système de containers maniéré, lourd, propriétaire et imposé. Du côté des avantages, ça "juste marche" et ça se met à jour tout seul.
Dès l'installation on peut choisir l'option "HWE kernel" (= Hardware Extension. On passe à un noyau 6.11 avec un support matériel encore meilleur) et l'option "Search for third-party drivers" qui installe des drivers non libres.
Le support LTS de base est de 5 ans, et le support étendu "pro" semble être de 5 ans supplémentaires (pour les mises à jour de sécurité). Cela oblige à créer un compte "Ubuntu Pro" mais pas de panique, on a droit à 5 souscriptions gratuites pour des serveurs perso.
** Choix des autres composants
Le couple Carte mère/CPU détermine le choix des autres composants.
Voici la liste du hardware commandé:
- Carte mère: Gigabyte X870E AORUS Pro
- CPU: Ryzen 9 9950X
- RAM: 4 barrettes de 48 GB
- deux SSD NVME Samsung 9100 Pro 2.0TB
- deux SSD NVME Samsung 990 EVO Plus 4.0TB
- Disque dur magnétique de 8.0TB
- Boitier, alim 1000W, refroidissement aio, carte son USB, et deux petits hubs USB-C vers USB-A.
- Un petit pavé numérique USB pour contrôler facilement quelques fonctions sur la machine hôte lorsque la VM de jeu est démarrée.
Et enfin la pièce du boucher: le GPU. Au moment de la réception des composants je n'ai pas encore la carte graphique finale donc le déploiement se fait avec une vieille RTX 2070 que j'ai récupérée. Ce ne change rien à la procédure car elle utilise les mêmes drivers Nvidia unifiés que toutes les autres RTX. La seule chose qui changera sera l'identifiant du matériel pour configurer la virtualisation, à adapter dans les fichiers de conf selon les outputs des commandes (procédure décrite plus bas), mais le principe reste le même.
J'utiliserai également temporairement, pendant l'installation de l'OS Ubuntu, un dongle USB vers Ethernet, car le driver du Realtek 2.5GbE intégré à la carte mère, n'est pas chargé à ce moment et le PC sera sans réseau, or on a besoin d'une connexion au moment de l'install pour faire les mises à jour et d'autres choses (bien sûr on peut installer l'OS sans réseau et apporter plus tard le driver de la NIC Realtek intégrée avec une clé USB. Mais c'est moins pratique).
** Préparation du PC
Avant d'installer le système, on commence par mettre à jour la carte mère dans le dernier niveau de firmware disponible. Pour ça je me suis rendu dans le "Download Center" sur le site de Gigabyte et j'ai tapé "X870E" dans le champ de recherche pour atterir directement sur la page de téléchargement des firmwares (dans la section "BIOS").
Ma carte est une rev. 1.1 livrée en firmware "FA", donc avec 5 versions de retard.
Il est malheureusement impossible de télécharger et d'installer directement le dernier firmware. Il faut passer par l'installation de chaque firmware intermédiare. Par conséquent la procédure est la suivante:
- mettre tous les fichiers (dézippés) sur une clé USB,
- démarrer le PC avec la clé USB insérée et aller dans les paramètres du BIOS, dans la section qui gère la mise à jour,
- effectuer toutes les mises à jour une par une.
Le PC redémarre deux fois pour chaque mise à jour dans mon cas. A chaque redémarrage on reste sur un écran noir qui semble interminable, mais au global c'est assez rapide: moins de 30 minutes suffisent pour appliquer toutes les mises à jour.
Il est inutile de commencer à faire des réglages dans le BIOS avant les upgrades, car tout va être réinitialisé.
Je suis maintenant à jour dans la dernière version (FA5b du 23 juin 2025), maintenant je fais les réglages désirés dans le BIOS:
- Indispensable: activation de la virtualisation (VT-x, ou AMD-V dans mon cas), du re-size BAR support, de IOMMU, et de SR-IOV.
- Facultatif: désactivation des devices internes Wi-fi, Bluetooth et HD Audio ; réglage du comportement "AC Power Loss" pour de redémarrer automatiquement après une coupure de courant ; choix du profil souhaité de contrôle des ventilateurs (compromis efficacité/silence). On fera plus tard un stress-test avec surveillance de la température.
C'est parti pour l'installation et la configuration complète du setup.
** Notes
Je ne précise pas "sudo" devant toutes les commandes mais "$" ou "#" selon qu'elles doivent être lancées en user ou en root.
Je ne précise pas qu'il faut rendre chaque script exécutable avec un chmod.
Dans les notes qui suivent le réseau NAT de l'hyperviseur est celui par défaut (192.168.122.0/24).
** Installation OS
- On installe Ubuntu Server 24.04.2 LTS en mode "HWE kernel" en utilisant le dongle USB-Eth.
- Type d'install: Server (pas minimal) sur le 1er nvme de 4TB, +openssh server.
- Il faut cocher la case "Search for third-party drivers" pour un support complet du matériel.
Dans mon cas j'ai oublié de cocher la case donc j'ai fait après l'install:
# apt install ubuntu-drivers-common- Création d'un compte utilisateur local "thom".
** Conf de base (à adapter)
# timedatectl set-timezone Europe/Paris
# vi .bashrc
export VISUAL=vim
export EDITOR=vim- Distribuer les clés SSH pour la connexion (~/.ssh/authorized_keys)
- Editer /etc/sudoers
- Permettre à root les fenêtres graphiques (à désactiver une fois que la configuration est complète):
# vi /root/.bashrc
export DISPLAY=:10.0
export XAUTHORITY=/home/thom/.Xauthority- Installation de remmina pour ouvrir des sessions graphiques distantes RDP ou autre:
# apt install remmina
$ vi .bashrc
alias remmina='/usr/bin/remmina >/dev/null 2>&1 &'** Rattachement à Ubuntu Pro
Cette étape est facultative, elle permet de bénéficier de paquets complémentaires testés et compilés par Canonical, et de mises à jour de sécurité pendant dix ans au lieu de cinq.
# dpkg -l | grep linux-generic # => linux-generic-hwe-24.04
# pro attach <clé générée sur le site d'Ubuntu>
# apt update && apt upgrade** Installation du driver de la NIC 2.5GbE intégrée à la carte mère
Le contrôleur de cette interface est un Realtek 8125.
# apt install build-essential dkms linux-headers-$(uname -r) git
# URL=https://github.com/awesometic/realtek-r8125-dkms/archive/refs/heads/master.zip
# wget -O r8125-dkms.zip $URL
# apt install unzip
# unzip r8125-dkms.zip
# cd realtek-r8125-dkms-master/
# ./dkms-install.sh
# ip a
# modprobe r8125
# ip a # vérifier
# vi /etc/netplan/*.yaml=> remplacer enx207bd2b2e60b par enp14s0 (à adapter selon son cas et le retour de la commande "ip a")
=> enlever le dongle USB-Eth et rebooter
** Drivers nvidia
Etant donné que je compte utiliser la carte RTX uniquement dans des machines virtuelles, il n'est pas nécesasire d'installer des drivers. Cependant si on souhaite utiliser le GPU sur l'OS hôte, on peut utiliser les commandes ubuntu-drivers devices / ubuntu-drivers autoinstall / ou bien apt install nvidia-driver-xxx
** Températures et ventilateurs (facultatif)
Installer de quoi surveiller le matériel:
# apt install lm-sensors nvme-cli linux-firmware amd64-microcode hwinfo
# sensors-detect=> valider toutes les réponses par défaut et ignorer le "no sensors were detected"
# sensors
# nvme smart-log /dev/nvme0
# nvme smart-log /dev/nvme1
# nvme smart-log /dev/nvme2
# nvme smart-log /dev/nvme3
# hwinfo
# nvme list
# nvidia-smi
# nvidia-smi --query-gpu=temperature.gpu,fan.speed --format=csv** Script: temps.sh (facultatif)
Voici un script pour regrouper les commandes de monitoring et afficher les infos souhaités
#!/bin/sh
temp=$(sensors |grep ^Tctl |awk '{print $2}')
echo "CPU : $temp"
temp=$(sensors |grep ^edge |awk '{print $2}')
echo "GPU : $temp"
for dev in /sys/class/nvme/nvme*/device; do
nvme=$(basename $(dirname "$dev"))
pci=$(basename $(readlink "$dev") |awk -F: '{print $2}')
temp=$(sensors |grep -A2 nvme-pci-${pci}00 |grep ^Composite |awk '{print $2}')
echo "$nvme : $temp"
done
#end#Note - si le GPU est passé en passthrough à une VM, la commande sensors ne récupèrera pas sa température, il faut passer la commande dans la VM. Alternativement, on a la commande "nvidia-smi" qui peut récupérer d'autres infos comme la consommation de VRAM et la consommation instantanée en Watts.
** Script: stress.sh (facultatif)
Le script suivant permet de vérifier le comportement du CPU sous forte charge en surveillant la température, afin de valider le compromis silence/refroidissement réglé dans le BIOS:
#!/bin/bash
CORES=$(nproc)
for i in $(seq 1 $CORES); do
yes > /dev/null &
done
sleep 20
killall yes
#end#** Tests refroidissement: fancontrol et stress-ng (facultatif)
Voici des exemples de commandes complémenatires pour contrôler les ventilateurs depuis l'OS (sur carte mère compatible) et de faire des stress-tests plus poussés
# apt install lm-sensors fancontrol stress-ng
# pwmconfig
# systemctl enable --now fancontrol
# systemctl status fancontrol
# stress-ng --cpu 0 --timeout 30s
# stress-ng --cpu 4 --vm 2 --io 2 --timeout 60s
# stress-ng --matrix 0 --timeout 30s --metrics-brief # benchmark** Optimisation pour matériel récent
- Installation des outils nécessaires + de quelques utilitaires couramment utilisés:
# apt install ethtool cpufrequtils htop lsof curl wget net-tools git dkms build-essential pciutils usbutils- Vérifier si amd-pstate est déjà actif (normalement, oui):
# grep -q 'amd-pstate' /sys/devices/system/cpu/cpu0/cpufreq/scaling_driver- Sinon, l'ajouter au démarrage de GRUB:
# sed -i 's/GRUB_CMDLINE_LINUX="/GRUB_CMDLINE_LINUX="amd-pstate=active /' /etc/default/grub- Ajouter aussi iommu au démarrage de GRUB:
# sed -i 's/GRUB_CMDLINE_LINUX="/GRUB_CMDLINE_LINUX="iommu=on /' /etc/default/grub- Mettre à jour GRUB et redémarrer:
# update-grub
# reboot** Conf du stockage (à adapter selon sa configuration et ses besoins)
- La commande suivante permet de lister les disques NVMe et les identifiants de devices PCIe correspondants:
# for dev in /sys/class/nvme/nvme*/device; do nvme=$(basename $(dirname "$dev")) ; pci=$(basename $(readlink "$dev")) ; echo "$nvme <-> $pci" ; done- On fait une partition ZFS sur le reste du disque système:
# apt install zfsutils-linux
# parted /dev/nvme2n1
(parted) mkpart primary 748789760s 100%
(parted) quit- Configuration des filesystems:
# zpool create -f system /dev/nvme2n1p4
# zpool create -f data /dev/nvme3n1
# zfs set compression=lz4 system
# zfs set compression=lz4 data
# zfs create system/public
# zfs create system/repository
# zfs create system/vm
# zfs set atime=off system/vm
# zfs set recordsize=128k system/vm
# zfs create data/vm
# zfs set atime=off data/vm
# zfs set recordsize=128k data/vm- Grosse partition sur le disque magnétique:
# zpool create -f hdd /dev/sda
# zfs set compression=lz4 hdd
# zfs create hdd/public
# zfs create hdd/backup
# zfs create hdd/repository
# zfs set quota=5T hdd/backup- Ownership/permissions:
# chown thom:thom /system/ /data/ /system/vm/ /system/repository/ /data/vm/ /hdd/ /hdd/backup/ /hdd/repository/
# chown nobody:nogroup /system/public /hdd/public
# chmod 777 /system/public /hdd/public** Filesystem chiffré
- Création d'un FS chiffré pour le backup de mes données:
# zfs create -o encryption=on -o keyformat=passphrase -o keylocation=prompt hdd/backup/thom- définir le mot de passe
- Au boot le FS n'est pas monté. Pour le monter:
# zfs load-key hdd/backup/thom
# zfs mount hdd/backup/thom- Pour le démonter:
# zfs unmount hdd/backup/thom
# zfs unload-key hdd/backup/thom- Pour vérifier l'état:
# zfs get encryption,keylocation,keyformat hdd/backup/thom** Montage des zpools au boot
- Sur mon système Ubuntu 24.04 j'ai un problème avec les Zpool/Zfs qui ne se montent pas toujours au démarrage. C'est causé par l'ordre de démarrage des services et peut-être le fait que tout le hardware n'est pas initialisé au moment ou les services ZFS démarrent. Pour corriger:
# systemctl disable zfs-import-scan.service
# systemctl enable zfs-import-cache.service
# zpool set cachefile=/etc/zfs/zpool.cache system
# zpool set cachefile=/etc/zfs/zpool.cache data
# update-initramfs -u
# systemctl edit zfs-import-cache.service[Unit]
After=/dev/nvme0n1.device /dev/nvme1n1.device /dev/nvme2n1.device /dev/nvme3n1.device
Requires=/dev/nvme0n1.device /dev/nvme1n1.device /dev/nvme2n1.device /dev/nvme3n1.device# systemctl daemon-reexec
# systemctl daemon-reload
# vi /etc/systemd/system/zfs-import-manual.service[Unit]
Description=Import ZFS pools manually after disks are ready
DefaultDependencies=no
After=/dev/nvme0n1.device /dev/nvme1n1.device /dev/nvme2n1.device /dev/nvme2n1p4.device /dev/nvme3n1.device
Requires=/dev/nvme0n1.device /dev/nvme1n1.device /dev/nvme2n1.device /dev/nvme2n1p4.device /dev/nvme3n1.device
[Service]
Type=oneshot
ExecStart=/sbin/zpool import -a
[Install]
WantedBy=multi-user.target# systemctl daemon-reload
# systemctl enable zfs-import-manual.service
** Faire un export NFS de /system/public pour le rendre accessible dans les VM:
(Facultatif):
# apt install nfs-kernel-server
# zfs set quota=200G system/public
# zfs set quota=200G hdd/public
# vi /etc/exports
/system/public 192.168.122.0/24(rw,sync,no_subtree_check,no_root_squash)
/hdd/public 192.168.122.0/24(rw,sync,no_subtree_check,no_root_squash)
# vi /etc/default/nfs-kernel-server
RPCNFSDCOUNT=8
RPCMOUNTDOPTS="--manage-gids"
# systemctl restart nfs-kernel-server** Conf environnement virtu KVM+passthrough
On en vient au plus important.
# apt install qemu-kvm virt-manager bridge-utils
# virt-manager- lancer virt-manager => enabler le network default au boot puis créer les pools:
repository ===> /system/repository
repository-hdd ===> /hdd/repository
nvme2-vm ===> /system/vm
nvme3-vm ===> /data/vm
- stopper le pool "default" et désactiver son autostart
Le tuto passthrough dont je me suis inspiré est le suivant: https://github.com/HarbourHeading/KVM-GPU-Passthrough
C'est parti:
# lscpu | grep "Virtualization"
# egrep -c '(vmx|svm)' /proc/cpuinfo
# lspci -nn |grep -E "NVIDIA|Samsung Electronics Co Ltd Device" |grep "\[....:....\]"Ces commandes montrent les identifiants du matériel, et pour ce qui me concerne:
> le GPU: 10de:1e84,10de:10f8,10de:1ad8,10de:1ad9
> les disques NVME: 144d:a810
> les ports USB4 de la carte mère: 1b21:2426
- Activer les iommu pour les devices PCI souhaités:
# vi /etc/default/grub
GRUB_CMDLINE_LINUX_DEFAULT="amd_iommu=on iommu=pt vfio-pci.ids=10de:1e84,10de:10f8,10de:1ad8,10de:1ad9,144d:a810,1b21:2426 isolcpus=8-15,24-31 nohz_full=8-15,24-31 rcu_nocbs=8-15,24-31"
# update-grub
# reboot- Pour préparer le passthrough, vérifier les IOMMU avec le script suivant:
# vi iommu.sh
#!/bin/bash
for d in /sys/kernel/iommu_groups/*/devices/*; do
n=${d#*/iommu_groups/*}; n=${n%%/*}
printf 'IOMMU Group %s ' "$n"
lspci -nns "${d##*/}"
done
#end#- Lancer le script
# ./iommu.sh==> IOMMU NVIDIA 01:00 : Group 15
==> IOMMU NVME 02:00 : Group 16
==> IOMMU NVME 03:00 : Group 17
- Isoler le GPU:
# vi /etc/modprobe.d/blacklist-gpu.conf
blacklist nouveau
blacklist nvidia
blacklist nvidia_drm
blacklist nvidiafb- Isoler les devices GPU, NVME, USB4
# vi /etc/modprobe.d/vfio.conf
options vfio-pci ids=10de:1e84,10de:10f8,10de:1ad8,10de:1ad9,144d:a810,1b21:2426
# vi /etc/initramfs-tools/modules
vfio
vfio_iommu_type1
vfio_pci
vfio_virqfd
# update-initramfs -c -k $(uname -r)
# reboot- Vérifier tout:
# lspci -k |grep -E "vfio-pci|NVIDIA"
# lspci -nnk -d 10de:1e84
# lspci -nnk -d 10de:10f8
# lspci -nnk -d 10de:1ad8
# lspci -nnk -d 10de:1ad9
# lspci -nnk -d 144d:a810==> vérifier qu'on a pour ces devices: "Kernel driver in use: vfio-pci"
** Activation des HugePages
Ceci permet d'optimiser la performance de la RAM.
- Vérification que c'est bien supporté:
# grep pdpe1gb /proc/cpuinfo |grep pdpe1gb
# zgrep HUGETLB /boot/config-$(uname -r) |grep -E "CONFIG_HUGETLBFS=y|CONFIG_HUGETLB_PAGE=y|CONFIG_ARCH_SUPPORTS_HUGETLBFS=y"=> doit retourner au moins CONFIG_HUGETLBFS=y et CONFIG_HUGETLB_PAGE=y
# test -f /proc/sys/vm/nr_hugepages && echo hugepages OK
# ls /sys/kernel/mm/hugepages/- Configurer les hugepages:
# mkdir /dev/hugepages
# echo "nodev /mnt/hugepages hugetlbfs pagesize=1G 0 0" >>/etc/fstab
# vi /etc/default/grub=> ajouter default_hugepagesz=1G hugepagesz=1G hugepages=160
(160 est le nombre de GB de ram à allouer aux hugepages, je mets le maximum de RAM qui sera alloué à une VM, à adapter selon le contexte).
Exemple:
GRUB_CMDLINE_LINUX_DEFAULT="default_hugepagesz=1G hugepagesz=1G hugepages=160 .....# update-grub
# reboot- Vérification:
# grep Huge /proc/meminfo
# sysctl -a |grep vm.nr_hugepages** Configuration de VM windows 11
Maintenant on installe la machine virtuelle de gaming. On lui alloue 16 vcpu dans l'exemple ci-dessous. Pour FS2024 c'est suffisant.
- Télécharger une image iso de windows 11 : https://www.microsoft.com/fr-fr/softwar … /windows11
- Télécharger l'iso des virtio guest tools pour windows: https://github.com/qemus/virtiso-x86/re … .1.271.iso
- !! Ne pas brancher d'écran maintenant
- Création d'un zvol compressé pour la VM (compromis idéal perf/fonctionnalités):
# zfs create -V 1024G -o volblocksize=64K data/win11-zvol
# zfs set compression=lz4 data/win11-zvol- Pour monitorer la compression en direct:
# zfs get compressratio data/win11-zvol- Créer la VM windows 11:
# virt-install \
--name=win11 \
--os-variant=win11 \
--memory=65536 \
--vcpus=16,sockets=1,cores=8,threads=2 \
--machine q35 \
--features kvm_hidden=on \
--controller type=scsi,model=virtio-scsi \
--cdrom=/system/repository/Win11_24H2_French_x64.iso \
--disk path=/dev/zvol/data/win11-zvol,format=raw,bus=scsi,cache=none,io=native \
--disk path=/system/repository/virtio-win-0.1.271.iso,device=cdrom,bus=sata \
--graphics spice \
--video virtio \
--network network=default,model=virtio \
--hostdev pci_0000_01_00_0 \
--hostdev pci_0000_01_00_1 \
--hostdev pci_0000_01_00_2 \
--hostdev pci_0000_01_00_3 \
--hostdev pci_0000_1a_00_0 \
--wait -1- Lors de l'insrtallation de Windows, il ne trouve aucun disque dur, c'est normal, il faut aller chercher le driver pour le disque virtio-scsi sur l'emplacement suivant: E:\vioscsi\w11\amd64
- Et pour la carte réseau: pareil, il faut prendre le driver dans dans E:\NetKVM\win11\amd64
- Après l'install, arrêter la VM et éditer le XML et mettre (sous <vcpu ...>):
<iothreads>1</iothreads>- Et modifier le contrôleur:
<controller type='scsi' index='0' model='virtio-scsi'>
<driver iothread='1'/>
</controller>- Suite: monter l'image iso des drivers de virtio (virtio-win-0.1.271.iso)
- Installer les guest tools (en administrateur) et les drivers manquants
- Fixer l'IP de la VM si nécessaire
- Ajouter la machine hôte dans l'etc/hosts (ouvrir notepad en administrateur) si nécessaire (dans C:\windows\system32\drivers\etc).
- Activer le NFS client pour pouvoir accéder au répertoire public sur la machine hôte: menu démarrer > fonctionnalités windows > activer > Services pour NFS > cilent
- Créer un raccourci sur le bureau vers \\host\system\public (et/ou \\host\hdd\public)
- Activer RDP: paramètres > système > bureau à distance (+ utilisateur à spécifier)
- Faire un test d'accès RDP
- Activer Windows
- Arrêter la VM win11, l'éditer dans virt-manager pour mettre video=None puis supprimer sound ICH9
- Editer le XML et remplacer <audio id='1' type='spice'/> par <audio id='1' type='none'/>
- Dans le XML mettre le CPU pinning + iothread:
<vcpu placement='static'>16</vcpu>
<iothreads>1</iothreads>
<cputune>
<vcpupin vcpu='0' cpuset='8'/>
<vcpupin vcpu='1' cpuset='24'/>
<vcpupin vcpu='2' cpuset='9'/>
<vcpupin vcpu='3' cpuset='25'/>
<vcpupin vcpu='4' cpuset='10'/>
<vcpupin vcpu='5' cpuset='26'/>
<vcpupin vcpu='6' cpuset='11'/>
<vcpupin vcpu='7' cpuset='27'/>
<vcpupin vcpu='8' cpuset='12'/>
<vcpupin vcpu='9' cpuset='28'/>
<vcpupin vcpu='10' cpuset='13'/>
<vcpupin vcpu='11' cpuset='29'/>
<vcpupin vcpu='12' cpuset='14'/>
<vcpupin vcpu='13' cpuset='30'/>
<vcpupin vcpu='14' cpuset='15'/>
<vcpupin vcpu='15' cpuset='31'/>
</cputune>- Ajouter les options suivantes dans la section <hyperv>:
<relaxed state='on'/>
<vapic state='on'/>
<spinlocks state='on' retries='8191'/>
<vpindex state='on'/>
<runtime state='on'/>
<synic state='on'/>
<stimer state='on'/>
<frequencies state='on'/>
<reenlightenment state='on'/>
<tlbflush state='on'/>
<ipi state='on'/>- Configurer l'utilisation des hugepages (sous la RAM):
<memory unit='KiB'>67108864</memory>
<currentMemory unit='KiB'>67108864</currentMemory>
<memoryBacking>
<hugepages>
<page size='1048576' unit='KiB'/>
</hugepages>
</memoryBacking>- Configuration du NUMA => inutile dans mon cas car le 9950X a un seul CCD/un seul noeud NUMA. Sinon pour vérifier les nodes NUMA sur le host:
# lscpu -e | grep -E 'CPU|[8-9]|1[0-5]|2[4-9]|3[0-1]'
# numactl --hardware=> pour forcer tout de même l'affinité NUMA sur un node, éditer le XML de la VM:
(attention à pinner uniquement les vcpu sur les threads d'un même node numa)
<numatune>
<memory mode='strict' nodeset='0'/>
<memnode cellid='0' mode='strict' nodeset='0'/>
</numatune>- Vérifier que la topologie CPU est bien 1-8-2 dans <cpu>
- Supprimer le SATA CDROM 2 + démapper l'image iso du SATA CDROM 1
- Supprimer les devices: Channel (spice), USB Redirectors, Display Spice
- Démarrer le VM et se connecter en RDP ou écran/clavier local
- Vérification de KVM et des iothreads depuis le host:
# ps -eLo pid,tid,class,rtprio,ni,pri,psr,pcpu,stat,wchan:14,comm | grep -Ei "kvm|ioth"=> on doit voir un thread nommé IOThread
- Dans la VM win11: installation du pilote unifié nvidia.
- Arrêter une dernière fois la VM win11
- Faire un backup de l'image initiale après cette fresh install:
# zfs snapshot data/win11-zvol@backup
# zfs send data/win11-zvol@backup | gzip > /system/repository/images/win11.img.gz- Ne pas oublier de backuper aussi le XML de la VM (virsh dumpxml win11).
- On peut relancer la VM et l'utiliser normalement.
** Infos complémentaires
- Pour faire une restauration de l'image initiale:
# zfs create -V 1024G -o volblocksize=64K data/win11-zvol
# gunzip -c /system/repository/images/win11.img.gz | zfs recv -F data/win11-zvol- On peut convertir un zvol en qcow2 si on change d'avis:
# dd if=/dev/zvol/pool/monzvol of=monzvol.raw bs=1M status=progress
# qemu-img convert -f raw -O qcow2 monzvol.raw monzvol.qcow2- Et dans l'autre sens pour convertir un qcow2 en zvol:
# zfs create -V 20G pool/monzvol
# qemu-img convert -f qcow2 -O raw monzvol.qcow2 /dev/zvol/pool/monzvol** Gestion poweron/poweroff VM
J'utilise un petit pavé numérique USB collé au boitier ATX pour contrôler le démarrage de la VM windows. Ce pavé numérique doit être branché sur un port USB qui n'est pas passé à la VM. On prévoit les fonctions suivantes (à ajuster selon ses besoins):
- La séquence "1 2 3 [entrée]" démarre la VM win11,
- la séquence "4 5 6 [entrée]" envoit une demande de shutdown à la VM win11,
- la séquence "7 8 9 [entrée]" provoque un arrêt immédiat de la VM win11.
Pour cela on va créer sur l'hôte les scripts de démarrage/arrêt et créer des comptes utilisateurs sans mots de passes qu'on appellera 123, 456 et 789 et dont le rôle sera juste de pouvoir lancer les scripts:
# useradd -m -d /home/123 -s /bin/bash --badname 123 && passwd -d 123
# useradd -m -d /home/456 -s /bin/bash --badname 456 && passwd -d 456
# useradd -m -d /home/789 -s /bin/bash --badname 789 && passwd -d 789(l'option --badname est là car sinon la commande useradd refuse une séquence de chiffres comme nom d'utilisateur)
# touch /root/win11_start.sh
# touch /root/win11_shutdown.sh
# touch /root/win11_stop.sh
# chmod +x /root/win11_*.sh- Créer le script de démarrage:
# vi /root/win11_start.sh
#!/bin/sh
/usr/bin/virsh list --all |grep " shut off$" |awk '{print $2}' |grep "^win11$" >/dev/null 2>&1 && \
/usr/bin/virsh start win11- Créer le script de shutdown:
# vi /root/win11_shutdown.sh
#!/bin/sh
/usr/bin/virsh list --all |grep " running$" |awk '{print $2}' |grep "^win11$" >/dev/null 2>&1 && \
/usr/bin/virsh shutdown win11- Créer le script d'arrêt:
# vi /root/win11_stop.sh
#!/bin/sh
/usr/bin/virsh destroy win11- Configurer le lancement auto du script start par le user 123:
# vi /home/123/.bashrc
case "$(tty)" in
/dev/tty[0-9]*) sudo /root/win11_start.sh;;
*) echo "logout";;
esac
logout- Configurer le lancement auto du script shutdown par le user 456:
# vi /home/456/.bashrc
case "$(tty)" in
/dev/tty[0-9]*) sudo /root/win11_shutdown.sh;;
*) echo "logout";;
esac
logout- Configurer le lancement auto du script stop par le user 789:
# vi /home/789/.bashrc
case "$(tty)" in
/dev/tty[0-9]*) sudo /root/win11_stop.sh;;
*) echo "logout";;
esac
logout- Et enfin, ajouter ces commandes dans sudoers pour permettre aux users 123, 456 et 789 d'effectuer leurs actions:
# vi /etc/sudoers
123 ALL=(ALL) NOPASSWD: /root/win11_start.sh
456 ALL=(ALL) NOPASSWD: /root/win11_shutdown.sh
789 ALL=(ALL) NOPASSWD: /root/win11_stop.sh** La deuxième VM: ia1
Quand la VM win11 n'est pas démarrée, on peut disposer des ressources pour un autre usage, dans mon cas: faire tourner des IA génératives sous Linux.
- Je déploie la VM ia1 depuis un template donc les settings pour le passthrough doivent être définis dans le XML après coup.
- J'alloue beaucoup de RAM à cette VM (160 GB) et je supprime le swap (swapoff /swap.img puis éditer le fstab pour commenter la ligne).
- J'ajoute 2 images disques qcow2 de 512 GB.
- Avant de démarrer la nouvelle VM, passer les PCI host devices:
01:00:0 NVIDIA Corporation TU104 [GeForce RTX 2070 SUPER]
01:00:1 NVIDIA Corporation TU104 HD Audio Controller
01:00:2 NVIDIA Corporation TU104 USB 3.1 Host Controller
01:00:3 NVIDIA Corporation TU104 USB Type-C UCSI Controller
02:00.0 Non-Volatile memory controller [0108]: Samsung (...) [144d:a810]
03:00.0 Non-Volatile memory controller [0108]: Samsung (...) [144d:a810]
(virt-manager va râler que certains devices sont déjà passés à la VM win11, c'est normal, on sait).
- Editer le XML et mettre la config pour allouer 32 vCPU:
<vcpu placement='static'>32</vcpu>
<iothreads>1</iothreads>
<cputune>
<vcpupin vcpu='0' cpuset='0'/>
<vcpupin vcpu='1' cpuset='16'/>
<vcpupin vcpu='2' cpuset='1'/>
<vcpupin vcpu='3' cpuset='17'/>
<vcpupin vcpu='4' cpuset='2'/>
<vcpupin vcpu='5' cpuset='18'/>
<vcpupin vcpu='6' cpuset='3'/>
<vcpupin vcpu='7' cpuset='19'/>
<vcpupin vcpu='8' cpuset='4'/>
<vcpupin vcpu='9' cpuset='20'/>
<vcpupin vcpu='10' cpuset='5'/>
<vcpupin vcpu='11' cpuset='21'/>
<vcpupin vcpu='12' cpuset='6'/>
<vcpupin vcpu='13' cpuset='22'/>
<vcpupin vcpu='14' cpuset='7'/>
<vcpupin vcpu='15' cpuset='23'/>
<vcpupin vcpu='16' cpuset='8'/>
<vcpupin vcpu='17' cpuset='24'/>
<vcpupin vcpu='18' cpuset='9'/>
<vcpupin vcpu='19' cpuset='25'/>
<vcpupin vcpu='20' cpuset='10'/>
<vcpupin vcpu='21' cpuset='26'/>
<vcpupin vcpu='22' cpuset='11'/>
<vcpupin vcpu='23' cpuset='27'/>
<vcpupin vcpu='24' cpuset='12'/>
<vcpupin vcpu='25' cpuset='28'/>
<vcpupin vcpu='26' cpuset='13'/>
<vcpupin vcpu='27' cpuset='29'/>
<vcpupin vcpu='28' cpuset='14'/>
<vcpupin vcpu='29' cpuset='30'/>
<vcpupin vcpu='30' cpuset='15'/>
<vcpupin vcpu='31' cpuset='31'/>
</cputune>
<cpu mode='host-passthrough' check='none' migratable='on'>
<topology sockets='1' dies='1' cores='16' threads='2'/>
<feature policy='require' name='topoext'/>
</cpu>- Ajouter dans les features:
<kvm>
<hidden state='on'/>
</kvm>
<hyperv mode='custom'>
<relaxed state='on'/>
<vapic state='on'/>
<spinlocks state='on' retries='8191'/>
<vpindex state='on'/>
<runtime state='on'/>
<synic state='on'/>
<stimer state='on'/>
<frequencies state='on'/>
<reenlightenment state='on'/>
<tlbflush state='on'/>
<ipi state='on'/>
</hyperv>
<vmport state='off'/>
<smm state='on'/>- Ajouter à la fin de la partie clock:
<clock offset='utc'>
<timer name='hypervclock' present='yes'/>
</clock>- Définir la quantité de RAM et configurer l'utilisation des hugepages:
<memory unit='GiB'>160</memory>
<currentMemory unit='GiB'>160</currentMemory>
<memoryBacking>
<hugepages>
<page size='1' unit='G'/>
</hugepages>
</memoryBacking>- Démarrer la VM et se loguer dedans.
- Changer son adresse IP (ne pas laisser celle du template).
- Effectuer la configuration système de base:
# apt update && apt upgrade
# echo "host:/system/public /public nfs defaults 0 2" >>/etc/fstab
# systemctl daemon-reload
# apt install lvm2 ubuntu-drivers-common lm-sensors
# ubuntu-drivers devices
# apt install nvidia-driver-575
# apt install python3-pip- On configure un filesystem /datap qui utilise en parallèle les deux ssd nvme 9100 en passthrough pour un max de perf:
# pvcreate /dev/nvme0n1 /dev/nvme1n1
# vgcreate vg_datap /dev/nvme0n1 /dev/nvme1n1- On crée une partition de swap au cas où, pour pouvoir faire "tourner" des LLM trop gros pour cette machine juste pour du test (ex. j'ai testé llama3.1:405b, on est à moins d'un token par minute) ou en cas de besoin:
# lvcreate -i2 -I64 -L 256G -n lv_swap vg_datap
# mkswap /dev/vg_datap/lv_swap
# swapon /dev/vg_datap/lv_swap
# blkid /dev/vg_datap/lv_swap
# echo "UUID=<UUID> none swap sw 0 0" >>/etc/fstab(remplacer l'UUID)
# swapoff -a
# swapon -a- Formater le filesystem data performant (j'ai choisi du xfs après comparaison des différentes options):
# lvcreate -i2 -I64 -l100%VG -n lv_datap vg_datap
# mkfs.xfs -K -d su=64k,sw=2 /dev/vg_datap/lv_datap
# mkdir /datap
# echo "/dev/vg_datap/lv_datap /datap xfs noatime,nodiratime,allocsize=1g,inode64 0 0" >>/etc/fstab
# systemctl daemon-reload
# mount /datap
# chown thom:thom /datap
# cd /
# ln -s datap data- Créer un autre filesystem moins performant pour les données froides (en striping aussi, sur les deux qcow2 de 512 GB, qu'on pourra étendre plus tard):
# pvcreate /dev/vdb /dev/vdc
# vgcreate vg_datarepo /dev/vdb /dev/vdc
# lvcreate -i2 -I64 -l100%VG -n lv_datarepo vg_datarepo
# mkfs.ext4 -m 0 -E stride=16,stripe-width=32,lazy_itable_init=1,lazy_journal_init=1 /dev/vg_datarepo/lv_datarepo
# mkdir /datap/repository
# echo "/dev/vg_datarepo/lv_datarepo /datap/repository ext4 defaults 0 0" >>/etc/fstab
# systemctl daemon-reload
# mount /datap/repository
# chown thom:thom /datap/repository- Monter le NFS sur le host pour échanger des données
# mkdir /public && mount /public- Faire un script pour surveiller l'occupation de ram/swap/vram:
# vi memuse.sh
#!/bin/bash
total=$(free -m |grep ^Mem: |awk '{print $2}')
total=$(expr $total / 1000)
used=$(free -m |grep ^Mem: |awk '{print $3}')
used=$(expr $used / 1000)
echo " RAM $(hostname): $used GB / $total GB"
swaptotal=$(free -m |grep ^Swap: |awk '{print $2}')
swaptotal=$(expr $swaptotal / 1024)
swapused=$(free -m |grep ^Swap: |awk '{print $3}')
swapused=$(expr $swapused / 1024)
echo "Swap $(hostname): $swapused GB / $swaptotal GB"
vramtotal=$(sudo nvidia-smi |grep MiB |head -1 |awk '{print $11}' |sed "s/MiB//")
vramtotal=$(expr $vramtotal / 1024)
vramused=$(sudo nvidia-smi |grep MiB |head -1 |awk '{print $9}' |sed "s/MiB//")
vramused=$(expr $vramused / 1024)
echo "VRAM $(hostname): $vramused GB / $vramtotal GB"- Pour mettre à jour le driver nvidia, quand un plus récent est disponible: Exemple quand le 575 a remplacé le 570:
# ubuntu-drivers devices
# apt remove nvidia-driver-570
# apt install nvidia-driver-575
# apt autoremove
# reboot** Arrêt auto de toutes les VMs
Sur le host, pour faire en sorte que les VM démarrées s'arrêtent proprement lors d'un shutdown/reboot:
# vi /etc/systemd/system/shutdown-libvirt-vms.service[Unit]
Description=Shutdown all running libvirt VMs
DefaultDependencies=no
Before=shutdown.target reboot.target halt.target
[Service]
Type=oneshot
ExecStart=/usr/local/bin/libvirt-shutdown-vms.sh
RemainAfterExit=true
[Install]
WantedBy=halt.target reboot.target shutdown.target# vi /usr/local/bin/libvirt-shutdown-vms.sh
#!/bin/bash
# Timeout (en secondes) pour attendre l'arrêt de chaque VM
TIMEOUT=60
running_vms=$(virsh list --name | grep -v '^$')
for vm in $running_vms; do
echo "stopping $vm"
virsh shutdown "$vm"
for i in $(seq 1 $TIMEOUT); do
if ! virsh domstate "$vm" | grep -q running; then
echo " $vm stopped"
break
fi
sleep 1
done
# Forcer l'arrêt si la VM n'a pas répondu
if virsh domstate "$vm" | grep -q running; then
echo " $vm forcedly stopped"
virsh destroy "$vm"
fi
done
#end## chmod +x /usr/local/bin/libvirt-shutdown-vms.sh
# systemctl enable shutdown-libvirt-vms.service** Etendre le drive C:\ du zvol Windows
Pour étendre le drive C:\ de la VM Windows si jamais il devient trop rempli:
- Sur le host:
# zfs set volsize=1536G data/win11-zvol- dans la vm win11: lancer un cmd.exe en admin
- désactiver WinRE:
reagentc /disable- supprimer la partition de récupération:
diskpart
> list volume
> select volume 4
> delete partition override
> exit- étendre C:\ dans l'outil de gestion des partitions disque
- pour réactiver WinRE si souhaité:
reagentc /enable(il essayera de créer une partition, sinon il utilisera un fichier dans C:\ si pas de place)
** Comparaison de la perf entre virtio-blk et virtio-scsi pour le stockage
- virtio-scsi:
<domain type='kvm'>
<iothreads>1</iothreads>
<devices>
<disk type='block' device='disk'>
<driver name='qemu' type='raw' cache='none' io='native' discard='unmap'/>
<source dev='/dev/zvol/data/win11-zvol'/>
<target dev='sda' bus='scsi'/>
<address type='drive' controller='0' bus='0' target='0' unit='0'/>
</disk>
<controller type='scsi' index='0' model='virtio-scsi'>
<driver iothread='1'/>
<address type='pci' domain='0x0000' bus='0x02' slot='0x00' function='0x0'/>
</controller>
</devices>
</domain>- virtio-blk: (pas de "<controller>", directement sur bus PCI)
<domain type='kvm'>
<iothreads>1</iothreads>
<devices>
<disk type='block' device='disk' iothread='1'>
<driver name='qemu' type='raw' cache='none' io='native' discard='unmap'/>
<source dev='/dev/zvol/data/win11-zvol'/>
<target dev='vda' bus='virtio'/>
<address type='pci' domain='0x0000' bus='0x00' slot='0x05' function='0x0'/>
</disk>
</devices>
</domain>** Pour effectuer une mise ajout apt update/apt upgrade sur le host:
Lors d'un apt upgrade, toujours vérifier que DKMS reconstruit bien le module pour le driver de la NIC 2.5GbE avant de rebooter (surtout si on est à distance).
Exemple lors d'une "grosse" mise à jour (ici on passe du noyau 6.11 au 6.14):
# apt upgrade
[...]
Do you want to continue? [Y/n] Y
[...]
Setting up linux-modules-6.14.0-24-generic (6.14.0-24.24~24.04.3) ...
Setting up linux-modules-extra-6.14.0-24-generic (6.14.0-24.24~24.04.3) ...
Setting up linux-headers-6.14.0-24-generic (6.14.0-24.24~24.04.3) ...
/etc/kernel/header_postinst.d/dkms:
* dkms: running auto installation service for kernel 6.14.0-24-generic
Sign command: /usr/bin/kmodsign
Signing key: /var/lib/shim-signed/mok/MOK.priv
Public certificate (MOK): /var/lib/shim-signed/mok/MOK.der
Building module:
Cleaning build area...
'make' -j16 KVER=6.14.0-24-generic BSRC=/lib/modules/6.14.0-24-generic modules....
Signing module /var/lib/dkms/r8125/9.015.00/build/src/r8125.ko
Cleaning build area...
r8125.ko.zst:
Running module version sanity check.
- Original module
- No original module exists within this kernel
- Installation
- Installing to /lib/modules/6.14.0-24-generic/updates/dkms/
depmod...
dkms autoinstall on 6.14.0-24-generic/x86_64 succeeded for r8125
* dkms: autoinstall for kernel 6.14.0-24-generic
...done.
[...]
Setting up linux-image-6.14.0-24-generic (6.14.0-24.24~24.04.3) ...
I: /boot/vmlinuz.old is now a symlink to vmlinuz-6.11.0-29-generic
I: /boot/initrd.img.old is now a symlink to initrd.img-6.11.0-29-generic
I: /boot/vmlinuz is now a symlink to vmlinuz-6.14.0-24-generic
I: /boot/initrd.img is now a symlink to initrd.img-6.14.0-24-generic
Setting up linux-image-generic-hwe-24.04 (6.14.0-24.24~24.04.3) ...
Setting up linux-hwe-6.14-tools-6.14.0-24 (6.14.0-24.24~24.04.3) ...
Setting up linux-headers-generic-hwe-24.04 (6.14.0-24.24~24.04.3) ...
[...]
Processing triggers for initramfs-tools (0.142ubuntu25.5) ...
update-initramfs: Generating /boot/initrd.img-6.11.0-29-generic
[...]
Processing triggers for linux-image-6.14.0-24-generic (6.14.0-24.24~24.04.3) ...
/etc/kernel/postinst.d/dkms:
* dkms: running auto installation service for kernel 6.14.0-24-generic
* dkms: autoinstall for kernel 6.14.0-24-generic
...done.
/etc/kernel/postinst.d/initramfs-tools:
update-initramfs: Generating /boot/initrd.img-6.14.0-24-generic
[...]
Found linux image: [...]
Adding boot menu entry for UEFI Firmware Settings ...
done
[...]
Running kernel version:
6.11.0-29-generic
Diagnostics:
The currently running kernel version is not the expected kernel version 6.14.0-24-generic.
Restarting the system to load the new kernel will not be handled automatically, so you should consider rebooting.
The processor microcode seems to be up-to-date.** Remplacement du GPU
- Update 11 aout 2025: j'ai reçu le nouveau GPU 5090. Il contient 2 devices PCI (au lieu de 4 sur la 2070) dont les identifiants (tels que listés par lspci) sont 10de:2b85 et 10de:22e8. Il faut donc mettre à jour la configuration sur le système hôte:
# vi /etc/default/grub
vfio-pci.ids=10de:2b85,10de:22e8,144d:a810,1b21:2426
# update-grub
# vi /etc/modprobe.d/vfio.conf
options vfio-pci ids=10de:2b85,10de:22e8,144d:a810,1b21:2426
# update-initramfs -c -k $(uname -r)
# reboot
# lspci -k |grep -E "vfio-pci|NVIDIA"
# lspci -nnk -d 10de:2b85
# lspci -nnk -d 10de:22e8- Ensuite, éditer le XML de la VM ia1 pour mettre à jour la conf:
# virsh edit ia1=> dans les <hostdev> supprimer les devices 01:00:2 et 01:00:3 (laisser 01:00:0 et 01:00:1)
- Première tentative de démarrage de la VM ia1: j'obtiens ce message d'erreur dans la console:
[ 8.195276] [drm:nv_drm_load [nvidia_drm]] *ERROR* [nvidia-drm] [GPU ID 0x00000a00] Failed to allocate NvKmsKapiDevice [ 8.195504] [drm:nv_drm_register_drm_device [nvidia_drm]] *ERROR* [nvidia-drm] [GPU ID 0x00000a00] Failed to register deviceEt le GPU n'est pas utilisable (pas détecté par la commande nvidia-smi).
Ce message d’erreur vient de nvidia_drm au moment où le module DRM du pilote NVIDIA essaie d’initialiser le GPU en mode KMS (Kernel Mode Setting) et échoue à obtenir un device via NvKmsKapiDevice.
Ce qui veut dire que ma configuration sous QEMU/KVM avec OVMF ne permet pas à nvidia_drm d’activer le mode KMS, car la carte n’est pas initialisée comme sur un bare-metal.
- Pour corriger cela il faut extraire la ROM du bios de la carte (dans la VM démarrée avec la carte en passthrough):
# echo 0000:01:00.0 > /sys/bus/pci/drivers/vfio-pci/unbind
# echo 0000:01:00.1 > /sys/bus/pci/drivers/vfio-pci/unbind
# echo 1 > /sys/bus/pci/devices/0000:01:00.0/rom
# cat /sys/bus/pci/devices/0000:01:00.0/rom > /root/gpu.rom
# echo 0 > /sys/bus/pci/devices/0000:01:00.0/rom
# echo 0000:01:00.0 > /sys/bus/pci/drivers/vfio-pci/bind
# echo 0000:01:00.1 > /sys/bus/pci/drivers/vfio-pci/bind- Déplacer le fichier au bon endroit pour Qemu et donner les droits dessus:
# mkdir -p /usr/share/qemu/vbios
# mv /root/gpu.rom /usr/share/qemu/vbios/
# chown libvirt-qemu:kvm /usr/share/qemu/vbios/gpu.rom- Editer de nouveau le XML de la VM ia1 (virsh edit ia1) et ajouter la ligne rom ici:
<hostdev mode='subsystem' type='pci' managed='yes'>
<source>
<address domain='0x0000' bus='0x01' slot='0x00' function='0x0'/>
</source>
<address type='pci' domain='0x0000' bus='0x0a' slot='0x00' function='0x0'/>
<rom file='/usr/share/qemu/vbios/gpu.rom'/>
</hostdev>
<hostdev mode='subsystem' type='pci' managed='yes'>
<source>
<address domain='0x0000' bus='0x01' slot='0x00' function='0x1'/>
</source>
<address type='pci' domain='0x0000' bus='0x0b' slot='0x00' function='0x0'/>
</hostdev> - Supprimer le device <video> de type virtio
(partie à supprimer):
<video>
<model type='virtio' heads='1' primary='yes'/>
<address type='pci' domain='0x0000' bus='0x00' slot='0x01' function='0x0'/>
</video>- Deuxième tentative de démarrage: c'est OK mais les drivers installés ne sont plus bons ! Or j'ai écrit plus haut que c'était les mêmes drivers, eh bien je me suis trompé: pour les cartes graphiques récentes, Nvidia ne fournit plus de prise en charge dans les drivers "nvidia-driver-xxx - distro non-free" mais plutôt dans la version "nvidia-driver-xxx-open - distro non-free".
Pour rectifier le tir, faire dans la VM:
# apt remove --purge nvidia-driver-575
# apt install nvidia-driver-575-open
# apt autoremove- Pour le cas de la VM win11: j'ai simplement supprimé les deux devices de la 2070 qui ne sont pas sur la 5090 (ils correspondent à un contrôleur intégré qui servait à utiliser un casque de VR, ou quelque chose comme ça, techno qui a été abandonnée par Nvidia depuis). La VM a démarré sans erreur et je n'ai pas eu besoin de mettre la rom de la carte dans le xml de la machine.
Et voilà le résultat :-)
** Conclusions
- Tout marche. J'ai installé l'OS hôte une seule fois, et la VM windows seulement 2 fois ! J'ai maintenant une liste sans fin de choses à tester pour apprendre à configurer des IA génératives locales, si jamais ça sert à quelque chose.
- J'ai mis trop de RAM et trop de stockage NVME pour cet usage, mais ça va me servir à faire tourner des VM en parallèle pour d'autres projets. Je pense réduire la RAM allouée à la VM IA et réduire la quantité de hugepages sur le host.
- La carte son USB est inutile (présence du device audio sur le GPU).
- L'ajout d'une carte graphique puissante (RTX 5090 au lieu d'une vieille carte de récup) n'est pas très utile pour juste tester des LLM, elle permet simplement de faire tourner quelques LLM supplémentaires en VRAM. En revanche, pour la génération d'images ou de vidéos sous ComfyUI c'est le jour et la nuit. La VM génère des images sur SD1.5 en 512x512 en environ 1 seconde et en 1024x1024 en environ 3 secondes (une fois le Ksampler chargé, dans le workflow de base, avec 20 passes). Et sur SD3.5 c'est rapide aussi (3 secondes en 512, 11 secondes en 1024, avec 30 passes). Je n'ai pas trop de repères pour comparer (juste que c'était beaucoup plus lent avec la RTX 2070). Et pour FS2024, j'attends le test.
A noter que les LLM gpt-oss:20b et gpt-oss:120b sont sortis en openweight pendant que je faisais mes premiers tests (=o3-mini et o4-mini, fournis en août 2025 par OpenAI). Le modèle 20B est très performant avec la RTX 5090, il semble hyper optimisé et très pertinent pour sa taille je trouve, et le modèle 120B, qui est bien meilleur, est parfaitement exploitable même s'il tourne en CPU only.
- Gigabyte a sorti une nouvelle version du firmware pour la carte mère (FA5) qui remplace les FA5a et FA5b, sauf que ces derniers ont disparu du site avec leurs release notes, donc je ne peux même pas savoir ce que corrige la FA5 pour moi. C'est agaçant. Je choisis de ne pas mettre à jour.
** Bonus: configuration du tunnel ssh pour la connexion distante
Cela me permettra plus tard de me connecter depuis chez moi au PC, qui sera déplacé à 200km, sachant qu'il sera en DHCP derrière une box internet inconnue (avec une IP inconnue sur son réseau local). C'est donc lui qui va initier la connexion vers chez moi, en vérifiant régulièrement que la connexion est up.
1/ Port knocking côté serveur (machine de rebond chez moi)
- Cette partie est facultative. Pour que le nouvel ordinateur vienne se connecter chez moi sur ma machine de rebond afin que je puisse y accéder via un tunnel SSH, on va configurer sur la machine de rebond un port knocking préalable.
- Il ne s'agit pas de considérer la séquence de port knocking comme réellement "secrète" (elle est dévoilée à chaque connexion) mais plutôt d'éviter de pourrir mes logs par des milliers de tentatives de connexion.
- Dans mon cas j'ai une box internet qui fait de la redirection de ports vers un routeur séparé, qui fait à son tour de la redirection de ports vers le réseau interne, et une VM avec une IP sur le network bridge, donc il faut configurer sur la box internet, puis sur le routeur séparé, chaque port à rediriger de la séquence.
- Ensuite configurer sur la machine de rebond le port knocking (exemple):
# apt install knockd
# echo "KNOCKD_OPTS=\"-i enp1s0\"" >>/etc/default/knockd
# vi /etc/knockd.conf
[SSH]
sequence = 12345,23456,34567,45678
seq_timeout = 30
start_command = ufw insert 1 allow from %IP% to any port 56789
tcpflags = syn
cmd_timeout = 30
stop_command = ufw delete allow from %IP% to any port 56789
# service knockd restart- Vérifier que ça passe bien:
# tail -f /var/log/knockd.logPuis essayer de se connecter
2/ ajout d'une seconde instance sshd (toujours côté serveur)
- On va configurer une deuxième instance du serveur SSHd, sur un autre port, pour gérer ce tunnel:
# cp /etc/ssh/sshd_config /etc/ssh/sshd_config_reverse
# vi /etc/ssh/sshd_config_reverse- Mettre à la fin (on reprend le port cible défini plus haut):
Port 56789
PidFile /var/run/sshd_reverse.pid
ListenAddress 0.0.0.0
PermitRootLogin no
PasswordAuthentication no
AllowTcpForwarding yes
GatewayPorts yes# cp /lib/systemd/system/ssh.service /etc/systemd/system/sshd-reverse.service
# vi /etc/systemd/system/sshd-reverse.service- Adapter ces lignes au nouveau service:
ExecStart=/usr/sbin/sshd -D -f /etc/ssh/sshd_config_reverse
Alias=sshd_reverse.service- Démarrer le service sshd n°2:
# systemctl daemon-reexec
# systemctl daemon-reload
# systemctl enable sshd-reverse
# systemctl start sshd-reverse3/ Ajout d'un compte user remote (toujours côté serveur)
On crée un user dédié à établir la connexion:
# useradd -m -d /home/remote -s /bin/bash remote
# su - remote
$ mkdir .ssh
$ chmod 700 .ssh
$ cd .ssh
$ touch authorized_keys
$ chmod 600 authorized_keys- Copier la clé ssh publique de mon user sur le nouveau PC dans authorized_keys.
- Suite: à faire sur la machine de rebond une fois que le setup est terminé:
# usermod -s /bin/false remote4/ Côté client (nouveau PC)
# useradd -m -d /home/remote -s /bin/bash remote
# su - remote
$ mkdir .ssh
$ chmod 700 .ssh
$ ssh-keygen -t rsa
$ cat .ssh/id_rsa.pub(copier cette clé publique sur la machine de rebond dans ~remote/.ssh/authorized_keys)
$ exit
# apt install knockd- connexion simple:
$ knock -d 10 machine_de_rebond 12345,23456, 34567, 45678
$ ssh -p 56789 remote@machine_de_rebond5/ Test du tunnel ssh
- Sur le nouveau PC, côté client:
knock -d 10 <machine_de_rebond> 12345 23456 34567 45678
ssh -N -R 2222:localhost:22 remote@machine_de_rebond -p 56789- Sur la machine de rebond (chez moi):
# vi ~/.ssh/config
Host super_pc
HostName localhost
Port 2222
User thom
ProxyJump thom@localhost
# ssh super_pc- autre possibilité: mettre un alias dans ~/.bashrc:
# vi .bashrc
alias ssh_superpc='ssh -X -p 2222 thom@localhost'- Pour backuper toutes les données (depuis chez moi en passant par le tunnel SSH) :
$ rsync -avz --delete -e ssh /data/ super_pc:/hdd/backup/thom/(!! attention de bien monter le FS chiffré au préalable sinon les données vont ailleurs ! ou ajouter un check avant).
- Pour rediriger un port d'un service tournant sur la VM ia1 afin de me connecter dessus depuis mon ordinateur perso:
$ ssh -o ProxyJump=super_pc -N -L 8188:localhost:8188 ia1(par exemple, pour comfyui, ou bien 8080 pour OpenWebUI) => comme ça je peux utiliser ComfyUI depuis chez moi en ouvrant http://localhost:8188 et c'est très fluide.
- Pour récupérer les fichiers créés dans le répertoire "output" de ComfyUI ou autres, on peut utiliser "sshfs". Exemple:
$ sshfs -o ProxyJump=super_pc ia1:/datap/ComfyUI/output ~/comfyui_output6/ Script: check_tunnel.sh sur sur le nouveau PC (le client, qui initie la connexion):
Ce script ouvre le tunnel SSH, vérifie qu'il est up et le relance si nécessaire:
#!/bin/bash
REMOTE_USER=remote
REMOTE_HOST=<machine_de_rebond>
REMOTE_PORT=56789
REVERSE_PORT=2222
LOCAL_PORT=22
PK_SEQUENCE="12345 23456 34567 45678"
KEEPALIVE_FILE=/home/remote/keepalive
MAX_AGE=120
# launch tunnel
if [ "$1" = "-s" ] ;then
/usr/bin/knock -d 10 $REMOTE_HOST $PK_SEQUENCE
/usr/bin/pkill -u $REMOTE_USER
sleep 0.5
/usr/bin/su - $REMOTE_USER -c "/usr/bin/ssh -N -f -R $REVERSE_PORT:localhost:$LOCAL_PORT $REMOTE_USER@$REMOTE_HOST -p $REMOTE_PORT"
fi
# check keepalive / launch tunnel if down
if [ "$1" = "-c" ] ;then
if [ -f "$KEEPALIVE_FILE" ]; then
AGE=$(($(date +%s) - $(stat -c %Y "$KEEPALIVE_FILE")))
[ "$AGE" -ge "$MAX_AGE" ] && /root/tunnel.sh -s && touch $KEEPALIVE_FILE
fi
fi
#end#- mettre ce script toutes les minutes dans la crontab pour maintenir le lien:
# crontab -e
* * * * * /root/tunnel.sh -c >>/root/tunnel.log 2>&17/ implémenter le touch du fichier keepalive depuis la machine de rebond
Le principe: la machine de rebond se connecte une fois par minute sur le nouveau PC pour faire un touch d'un fichier.
- En tant que remote@machine_de_rebond: générer une clé RSA et copier la clé publique sur le nouveau PC dans /home/remote/.ssh/authorized_keys
- Mettre la commande de keepalive dans la crontab:
# crontab -e
* * * * * ssh -p 2222 remote@localhost "touch keepalive"** Autres considérations:
- Je vais essayer de créer une autre VM sur le nouveau PC, utilisable localement avec un écran et clavier/souris, en essayant de passer en passthrough le port HDMI interne de la carte mère et le port USB 3.2 "solitaire". Cela permettrait d'avoir un "autre" PC local pour la bureautique, toujours up, et séparé de la machine de gaming. En utilisant un transmetteur HDMI sans fil (50 eur sur Amazon) et un clavier/souris sans fil, on pourrait avoir ce PC séparé un peu "loin" (=pas collé au boitier). Je vais tester ça.
- J'ai découvert qu'on peut éventuellement utiliser une carte graphique en passthrough *sans* brancher directement un écran dessus (avec looking glass: https://looking-glass.io/). Ca permettrait d'avoir par exemple, une machine sous Linux dans laquelle on peut ouvrir une VM dans une fenêtre, qui dispose du GPU en passthrough, et qui affiche la sortie de la carte graphique avec une perf proche du bare metal. Donc je vais voir à tester ça.
Hors ligne
#2 Hier à 19:22
- krodelabestiole

Re : Retour d'exp. passthrough RTX5090 dans une VM win 11 sous Ubuntu 22.04
merci pour l'info !
(et le tldr surtout hihi)
je viens justement de rajouter un container "gaming" à mon serveur mini pc minisforum amd, du coup je viens de faire le tour des solutions (docker, et bureau virtuel / stream fullHD) :
- gow (qui fonctionne le mieux pour moi)
- steamos par linux server, qui est en pleine transition, je suis très curieux de ce que ça va donner, qui sera apparemment simple, complet, et accessible depuis un navigateur : https://github.com/linuxserver/docker-steamos/issues/27
- et steam headless qui transitionne aussi de debian (qui n'a pas voulu reconnaître mon iGPU récent) vers arch.
(mais je ne veux pas de windows)
jusqu'ici tout fonctionne parfaitement avec gow, ce sont des solutions qui me semblent très prometteuses, je n'ai plus qu'à investir dans une interface occulink et une carte graphique !
la containerisation évite de cloisonner les ressources, mais ce n'est pas possible avec windows.
si un jour je trouve un jeu pas dispo sur linux ça m'embêtera peut-être, mais je ne joue heureusement pas souvent à des jeux "compétitifs".
nouveau forum ubuntu-fr on en parle là : refonte du site / nouveau design
profil - sujets récurrents - sources du site
Hors ligne
#3 Hier à 23:34
- RaphaelG
Re : Retour d'exp. passthrough RTX5090 dans une VM win 11 sous Ubuntu 22.04
Bravo pour ce gros pavé.
Contrairement à kro, je n'ai pas trouvé cela tldr. C'est copieux mais si on a un gros appétit, ça passe bien.
J'ai une petite question :
Dans le titre tu fais référence à Ubuntu 22.04.
Bizarre pour un projet si ambitieux de partir avec une vielle version de l'OS.
Surtout qu'au chapitre "Choix de l'OS", tu parles d'Ubuntu Server 24.04.
Je me suis dit que tu avais du faire une faute de frappe dans le titre.
Mais au chapitre "Conf environnement virtu KVM+passthrough", on voit que tu installes le paquet qemu-kvm. Hors, ce paquet que j'ai bien connu sur des vieilles versions de Debian, n'existe pas dans les dépôts de la 24.04.
Pourrais tu nous en dire plus ?
Dernière modification par RaphaelG (Hier à 23:37)
Hors ligne